3、树莓派人脸识别-人脸检测与识别实践部分
传统的人脸识别算法一般需要较高的计算资源,在树莓派上实现会很卡,下面是极简版的人脸识别。
代码文件夹链接如下链接: https://pan.baidu.com/s/1sWnvG7ChoFbkMUAs6nSCsQ?pwd=rdmt
参考文章:https://www.instructables.com/Real-time-Face-Recognition-an-End-to-end-Project/
运行代码:
- 拷贝文件目录到树莓派,打开命令行,进入文件目录
- ptyhon 01_face_dataset.py (这里输入python 01 之后按tab会自动补齐文件名)
- 输入id (任意数字,1-10最佳)
- 等待摄像头拍照,照片会存进dataset文件夹,名字跟id和顺序有关
- python 02_face_training.py (这里输入python 02 之后按tab会自动补齐文件名)
- 训练好的文件会放在trainer文件夹内
- python 03_face_recognition.py (这里输入python 03 之后按tab会自动补齐文件名)
- 这里会打开摄像头,面部贴近摄像头会显示识别信息,id对应03_face_recognition.py代码中的names数组名字,中文会乱码所以直接用英文缩写就好(比如 张三改成San Zhang )
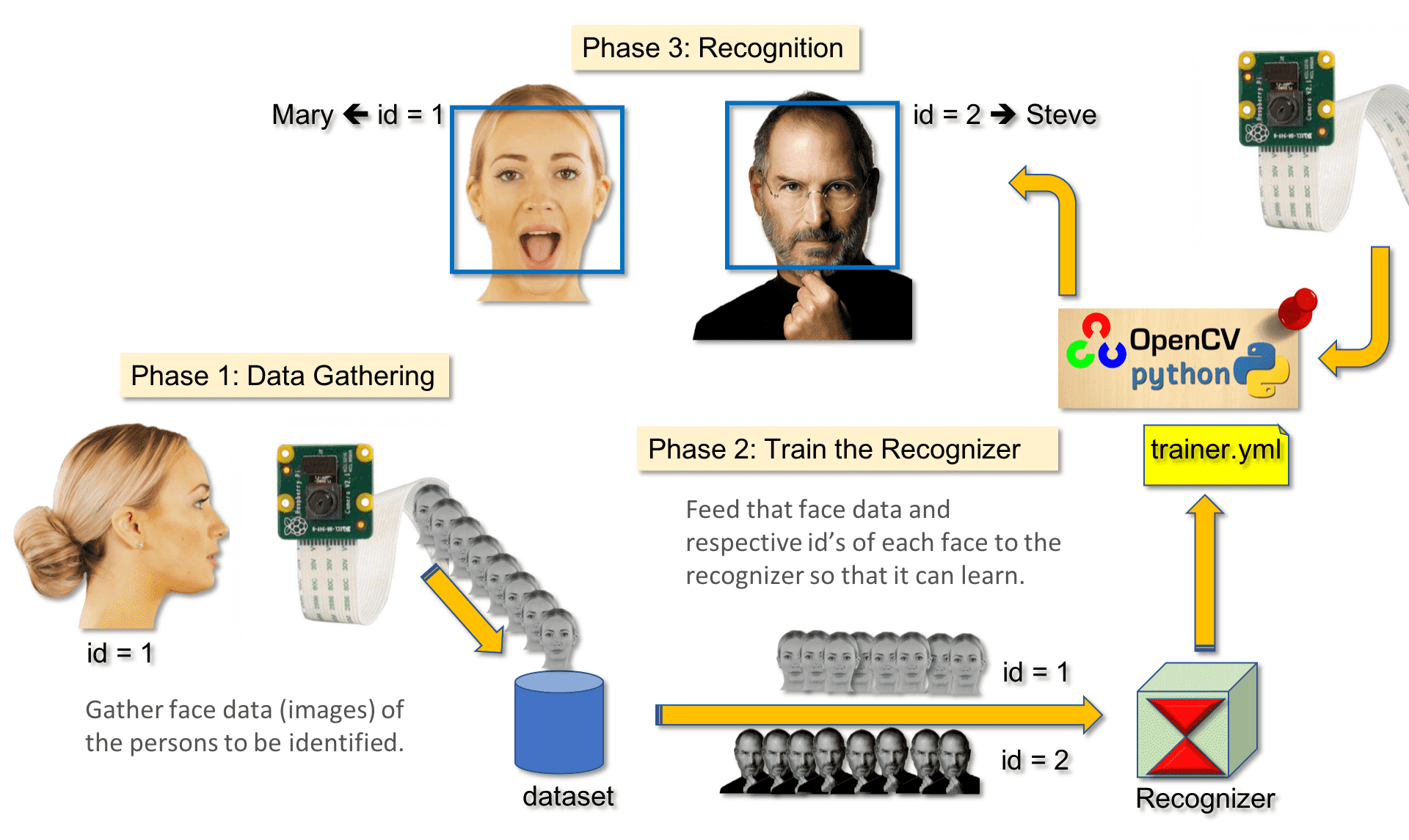
1、01_face_dataset(捕捉人脸存储到文件用于训练,保存到dataset文件夹)
- 下面这段代码使用 OpenCV 捕获摄像头中的视频帧,并利用 haarcascade_frontalface_default.xml 文件来进行人脸检测。
- 每输入一个数字人脸ID,并在数据集文件夹中创建一个名为 “User.[face_id].[count].jpg” 的新文件来保存每个采集到的人脸样本。
- 程序将等待直到采集到30个人脸样本或按下 ESC 键,然后清理资源并退出程序。
1 | # 从多个用户中捕获多个人脸并将其存储在数据库(数据集目录)中 |
2、02_face_training(训练人脸数据,保存到trainer文件夹)
- 下面这段代码通过调用 OpenCV 的人脸识别器和人脸检测器,对存储在数据库中的多个人脸图像进行训练。
- 函数
getImagesAndLabels()用于获取数据库中的人脸图像和对应的标签数据。- 然后,使用 LBPH 识别器对这些人脸图像进行训练,并将训练好的模型保存到 trainer/trainer.yml 文件中。
- 最后,程序输出训练过的人脸数量,并退出程序。
1 | import cv2 |
3、03_face_recognition
- 下面这段代码使用
cv2.VideoCapture实时获取摄像头捕获的视频图像,然后使用人脸检测器检测图像中的人脸。- 对于检测到的每个人脸,使用训练好的 LBPH 人脸识别器进行识别。
- 如果置信度(confidence)小于100,则认为识别成功,并根据 ID 获取对应的名字。否则,将 ID 设置为 “unknown”。
- 最后,在图像上显示出识别结果。
- 程序会持续地从摄像头中获取图像,并进行实时的人脸识别,直到用户按下 ESC 键退出程序。
1 | import cv2 |
到这里已经完成了树莓派人脸识别的课程设计,但是并不能得到很好地GPA。
故很容易想到用pyqt做一个简单界面,链接数据库做数据的存储(mysql并不能正确配置armhf,所以用平替MariaDB尝试了一下,体验很差),经过笔者的尝试效果并不理想,如果你是使用8核的主板可以尝试一下,4核真的很卡,所以我不建议在这里花时间去做。
所以这里建议直接在自己的笔记本电脑上做其他的人脸识别实验
- (CSDN上可以搜到,有人做了很系统的总结)Python3.0+OpenCV4+PyQt5+Mysql8+dlib+conda环境的人脸识别,其中环境使用Anaconda配置的虚拟环境,活体检测使用的dlib眨眼检测(一般我们使用的都是普通的2D相机,不同于景深信息相机和3D结构光相机,不能很好的进行活体检测),界面设计用QT Designer,人脸识别主要使用OpenCV库的一些函数,效果比较好的是ResNet-SSD残差网络,使用affine transformations进行仿射变换,使用2015Google的FaceNet做人脸识别,使用SVM只支持向量机更好的处理向量数据,使用PyMysql操作数据库。
- (Kaggle上直接找Olivetti数据集,里面有人做的案例可以参考)使用现有的数据集比如Olivetti数据集(40人x10张人脸灰度图-不同时间、表情、细节),做PCA主要成分分析,在数量足够多的情况下进行局部特征分析、全局分析和混合分析找到三种模型中accury交叉验证准确率得分最高的模型,进行参数优化得到最优的模型用于人脸识别实验的结果。
上面两个实验提供了两个很好地思路,一种是实体的检测,一种是照片的检测,这里想到之前机器视觉有人答辩的时候老师问他准确率怎么有90+,正常70就很好了,他直接懵(因为他用的是手机照片放在摄像头做的测试,环境影响不大所以检测差不不大,实际使用实体人脸的话准确率也在60左右。)
到这里满绩完全没有问题,如果你想让老师眼前一亮到时候科研项目、保研考研一类看好你,可以往下看,
你可以在自己的论文内加入一些比较权威的内容,比如在bilibili上搜CVPR论文,之后关注加v拿资料,可以在论文内找找看有没有感兴趣的加到自己的课程设计内,比如人脸识别&检测、人脸生成&合成&重建&编辑、人脸反欺骗这这些方面入手。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Ruiqy~!
 微信
微信 支付宝
支付宝






