第14章 数据分析示例
本章知识小结:
- 1、结构化数据 (表格型数据、多维数组矩阵、键位列关联的SQL表、均匀或非均匀的时间序列)
- 2、全局解释器锁GIL(防止解释器同时执行多个Python指令)
- 3、numpy、pandas、matplotlib、scipy、scikit-learn、statsmodels
- 4、处理\处置\ 规整 (munge\munging\wrangling)
- 5、伪代码:用一种类是代码的形式描述算法或过程
- 6、语法糖:并不增加新特性,但便利于代码编写的编程语法
1、从Bitly获取1.USQ.gov数据
1.1 纯Python时区计数
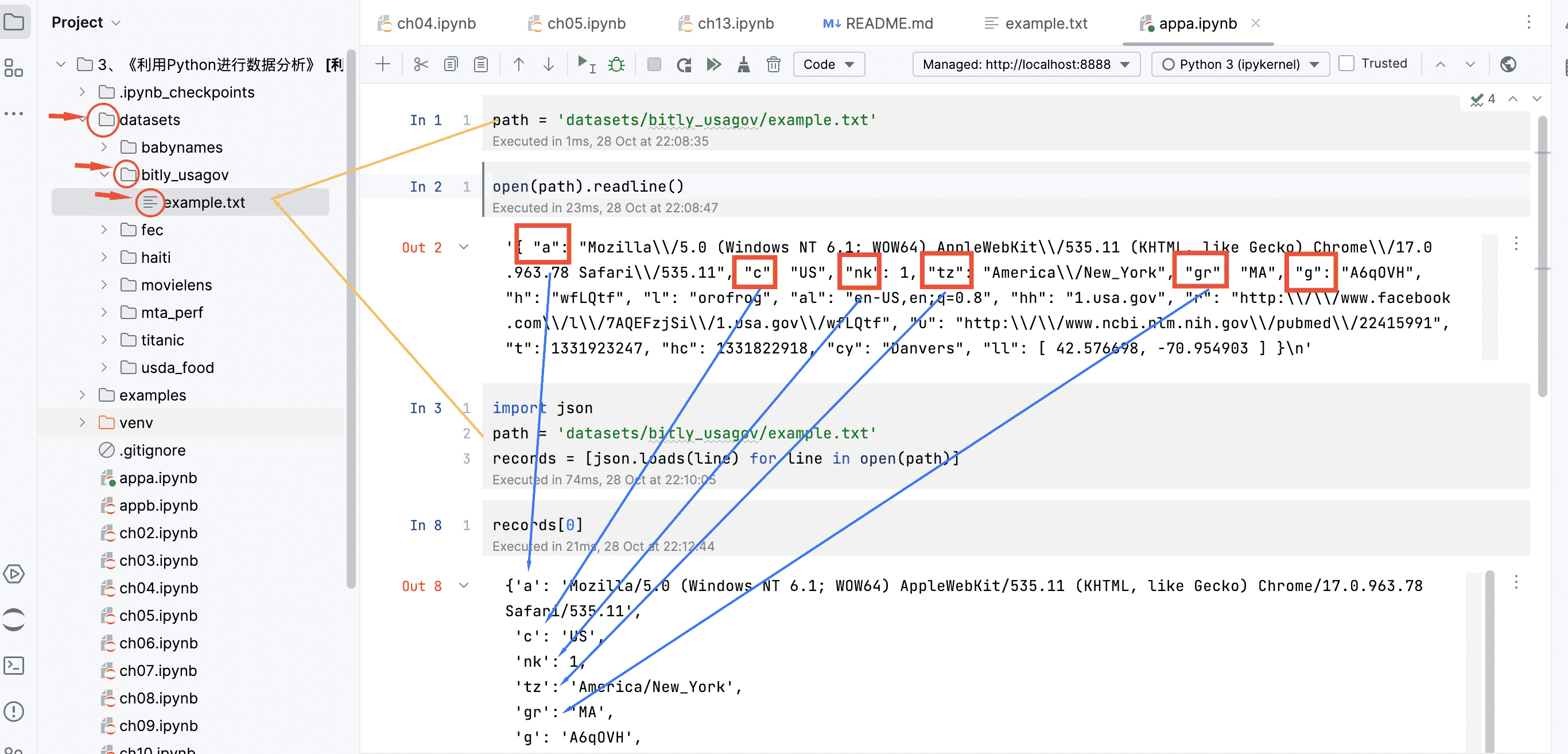
1 | import json |
1.2 用pandas进行时区计数
1 | import json |
2、MovieLens 1M数据集
3、美国1880~2010年的婴儿名字
4、美国农业部视频数据库
5、2012年联邦选举委员会数据库
6、本章小结(一些扩充的内容)
6.1 高阶numpy
6.2 更多IPython系统相关内容
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Ruiqy~!
 微信
微信 支付宝
支付宝
相关推荐






评论
系列文章



















