第1章
1、实验环境Anaconda
1.1 为什么用Anaconda?
- 1、自带了一大批常用的数据科学包(150+),不需要自己一个一个配置
- 2、conda便于管理Python包
- 3、可以创建自己的虚拟环境,在环境里面选择自己想要的版本的包
1.2 CUDA
英伟达(NVIDIA)显卡,也叫GPU,安装PyTorch需要指定GPU版本(没有就是None)
Windows可能有,Mac没有,Windows在命令行输入下命令,查看自己的CUDA版本,及时更新
1.3 配置环境pytorch
可以看这个起步(安装Python、PyCharm、Anaconda)
虚拟环境名叫pytorch,进入虚拟环境
2、PyTorch加载数据
2.1 拿到指定目录图片列表
直接解释代码,总的来说就是学会怎么拿数据,注:
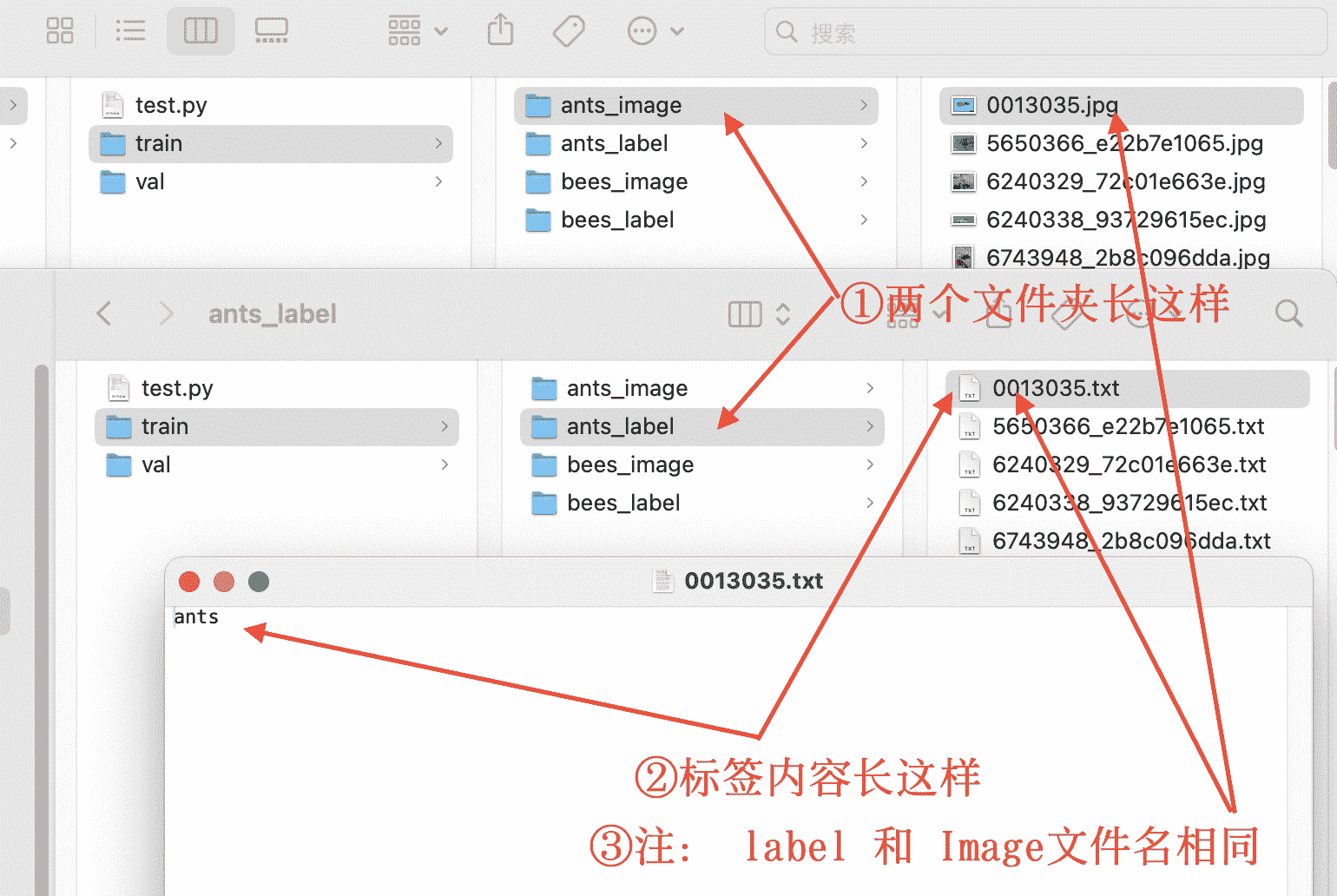
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
from torch.utils.data import Dataset, DataLoader
import os
from PIL import Image
from torchvision import transforms
class MyData(Dataset):
def __init__(self, root_dir, image_dir, label_dir, transform=None):
self.root_dir = root_dir
self.image_dir = image_dir
self.label_dir = label_dir
self.image_path = os.path.join(self.root_dir, self.image_dir)
self.label_path = os.path.join(self.root_dir, self.label_dir)
self.image_list = os.listdir(self.image_path)
self.label_list = os.listdir(self.label_path)
self.transform = transform
self.image_list.sort()
self.label_list.sort()
def __getitem__(self, idx):
img_name = self.image_list[idx]
label_name = self.label_list[idx]
img_item_path = os.path.join(self.root_dir, self.image_dir, img_name)
label_item_path = os.path.join(self.root_dir, self.label_dir, label_name)
img = Image.open(img_item_path)
with open(label_item_path, 'r') as f:
label = f.readline()
if self.transform:
img = transform(img)
return img, label
def __len__(self):
assert len(self.image_list) == len(self.label_list)
return len(self.image_list)
transform = transforms.Compose([transforms.Resize(400), transforms.ToTensor()])
root_dir = "/Users/ruiqingyan/Code/PyCharm/3、~PyTroch快速入门/数据集/练手数据集/train"
image_ants = "ants_image"
label_ants = "ants_label"
ants_dataset = MyData(root_dir, image_ants, label_ants)
img0, label0 = ants_dataset[0]
img0.show()
print(label0)
|
2.2 Tensorboard视图
(在编译环境)先在写代码,生成文件 , 新版本从tensorboardX里面导包
(在终端)之后在终端中打开文件 , 需要下载charset_normalizer包
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
from tensorboardX import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
image_path = "/Users/ruiqingyan/Code/PyCharm/3、~PyTroch快速入门/数据集/练手数据集/train/ants_image/5650366_e22b7e1065.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
writer.add_image("train", img_array, 1, dataformats='HWC')
for i in range(100):
writer.add_scalar("y=2x", 2*i, i)
writer.close()
|
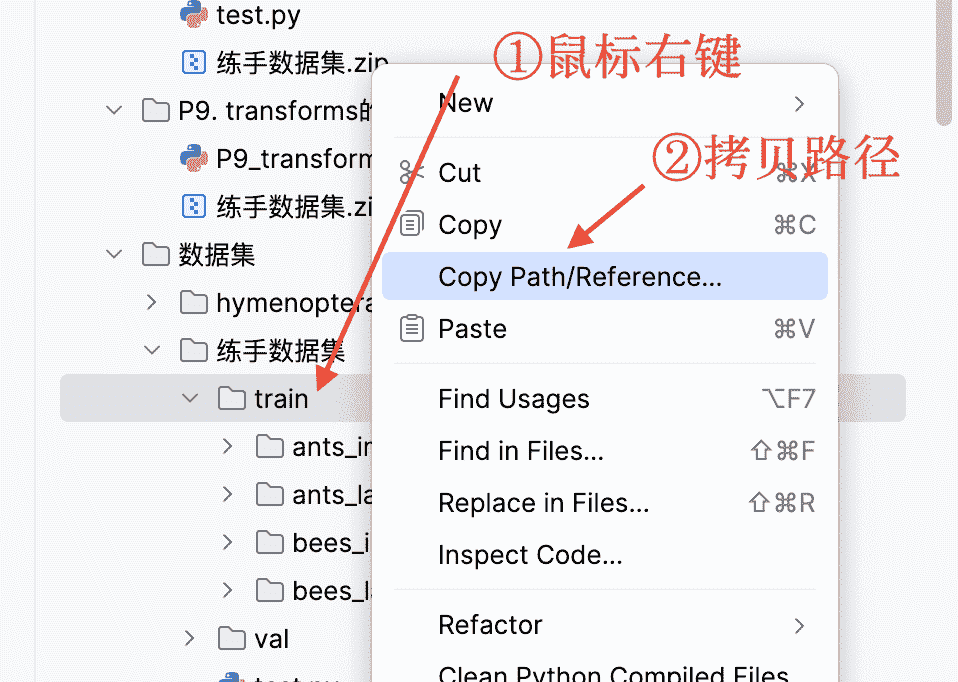
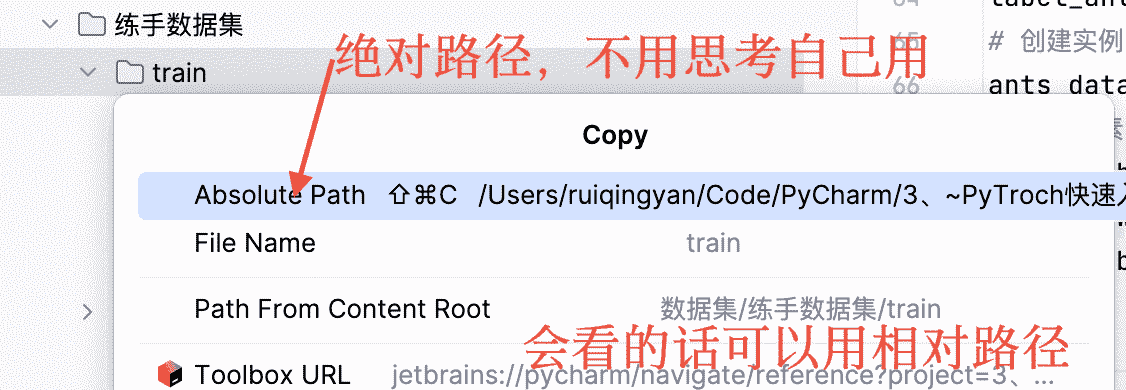
这里打开tensorboard的终端地址可能不是程序的地址,注意路径问题,不会用相对路径里面logs可以拷贝绝对路径用
之后在当前目录终端,输入(第一个命令下载必要包,第二个命令打开los目录下的tensorboard视图):
1
2
3
| pip install tensorboard
pip install --upgrade charset-normalizer
tensorboard --logdir=logs
|


1
2
3
4
5
|
from torchvision import transforms
transform = transforms.Compose([transforms.Resize(400), transforms.ToTensor()])
|
下面介绍下tensorform工具及自己创建工具,主要img_PIL要传入自己的图片URL
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| from PIL import Image
from torchvision import transforms
from tensorboardX import SummaryWriter
writer = SummaryWriter("logs")
img_PIL = Image.open("/Users/ruiqingyan/Code/PyCharm/3、~PyTroch快速入门/数据集/练手数据集/train/ants_image/6743948_2b8c096dda.jpg")
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img_PIL)
writer.add_image("ToTensor",img_tensor,1)
trans_norm = transforms.Normalize([0,3,1],[9,3,3])
img_norm = trans_norm(img_tensor)
writer.add_image("Normalize",img_norm,2)
trans_resize = transforms.Resize((512,512))
img_resize = trans_resize(img_PIL)
img_resize = trans_totensor(img_resize)
writer.add_image("Resize",img_resize,3)
trans_resize_2 = transforms.Resize(512)
trans_compose = transforms.Compose([ trans_resize_2 , trans_totensor ])
img_resize_2 = trans_compose(img_PIL)
writer.add_image("Resize",img_resize,4)
trans_random = transforms.RandomCrop(512)
trans_compose_2 = transforms.Compose([trans_random,trans_totensor])
for i in range(10):
img_corp = trans_compose_2(img_PIL)
writer.add_image("RandomCrop", img_corp, i)
writer.close()
|
写好之后在终端打开视图,使用如下命令:
1
| tensorboard --logdir=logs
|






总结,关注transforms.xxx的输入输出,多看官方文档,不同步数可以对应不同的结果。
3、torchvision中数据集的使用
进入pytorch给的数据集API文档https://pytorch.org/vision/0.9/

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
writer = SummaryWriter("p10")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
writer.close()
|
在终端,输入下面命令查看图片
1
| tensorboard --logdir=p10
|
4、DataLoader使用
进入pytorch给的dataloader文档https://pytorch.org/docs/1.8.1/data.html?highlight=dataloader#torch.utils.data.DataLoader

1
2
3
4
5
6
|
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=2, persistent_workers=False)
|
下面是一个简单的例子,我们在第三步的时候下载了CIFAR10数据集,进行Dataloader打包输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("Epoch: {}".format(epoch), imgs, step)
step = step + 1
writer.close()
|

 微信
微信 支付宝
支付宝
























